claude 3 注册及介绍
前言
就在3月5号凌晨,OpenAI 最大的竞争对手 Anthropic 发布了新一代 AI 大模型系列 ——Claude 3!!!!
一石惊起千层浪! 各大网友,又又又开锅了!
官网链接:https://www.anthropic.com/claude
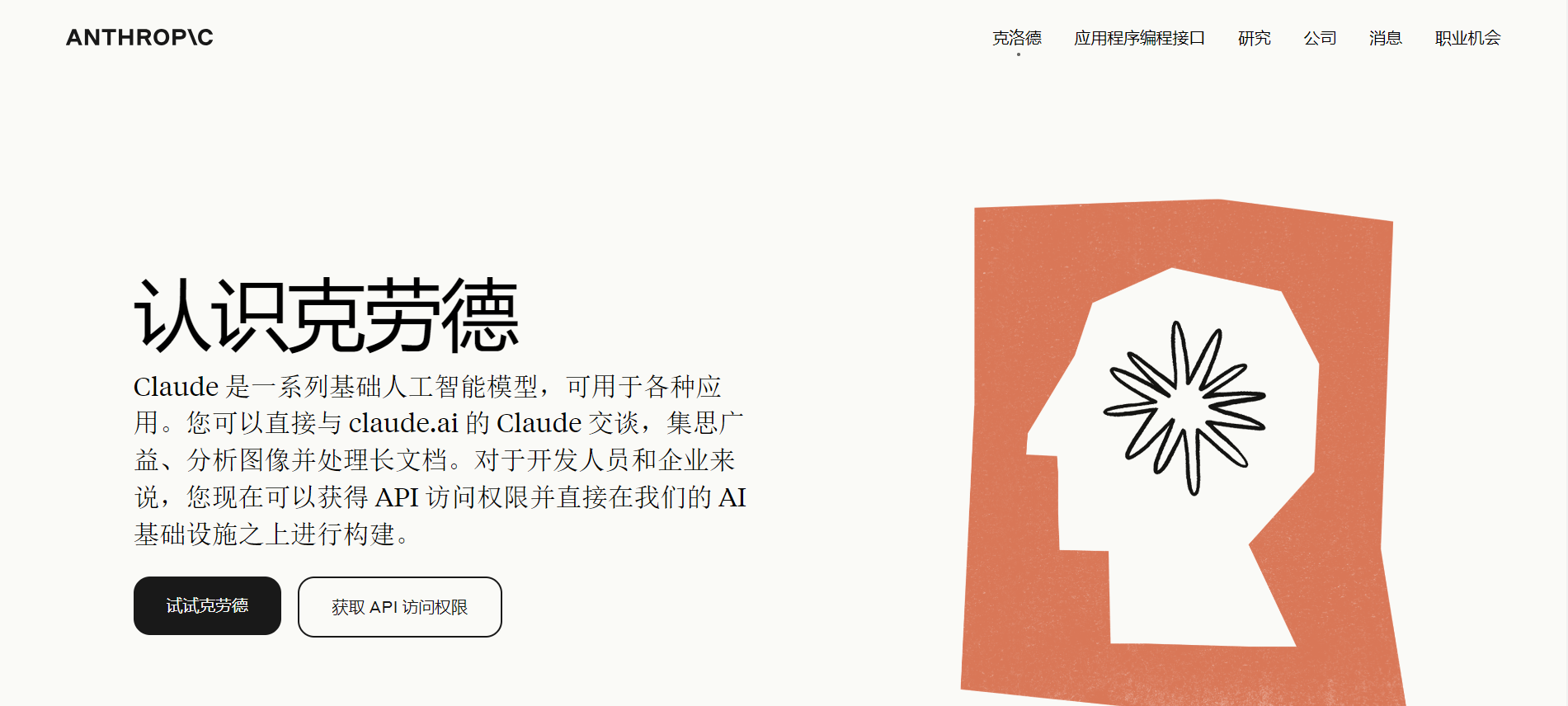
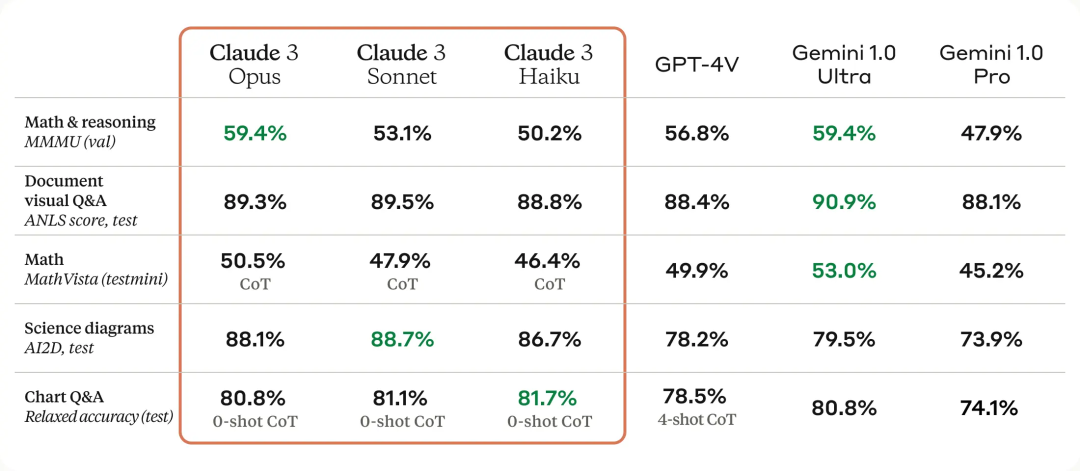
再看下它推出的三个模型:Opus、Sonnet、Haiku。从官网的图中介绍可以看出它们对应的特点。Opus无疑是最好的。
Claude 3 模型与竞品模型在多个性能基准上的比较,可以看到,最强的 Opus 全面优于 OpenAI 的 GPT-4。

简单的解释一下这里 0-shot是指没有给出例子的前提下完成的任务,可以看到图中的Claude3 Opus达到90.7%的准确率,用的是0-shot,GPT4是8-shot,达到了74.5%(MGSM,多语言数学推理这个测试集)。
可见Claude3最大的提升点就是:逻辑推理能力。
例子
看一下网友给出的测试
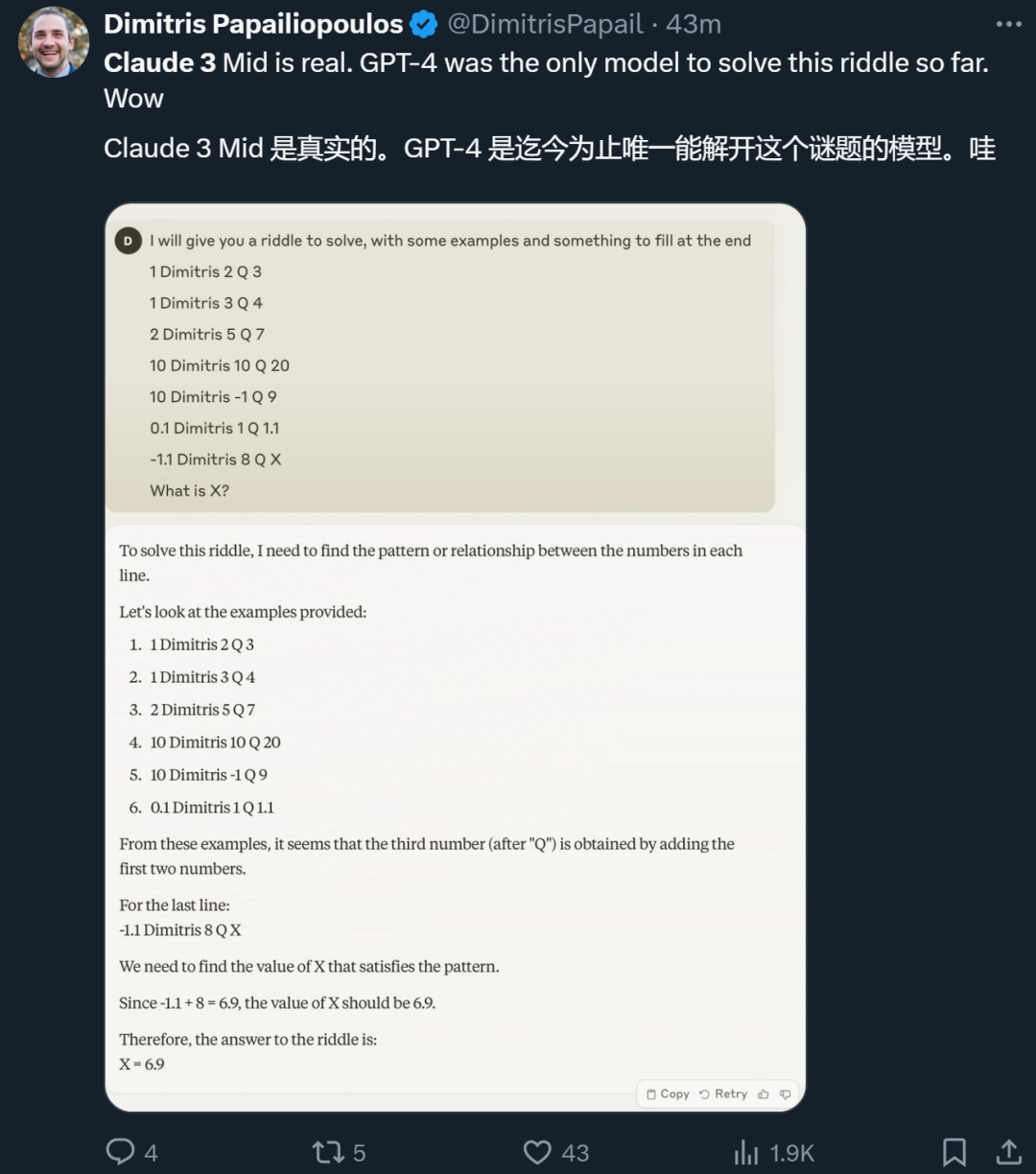

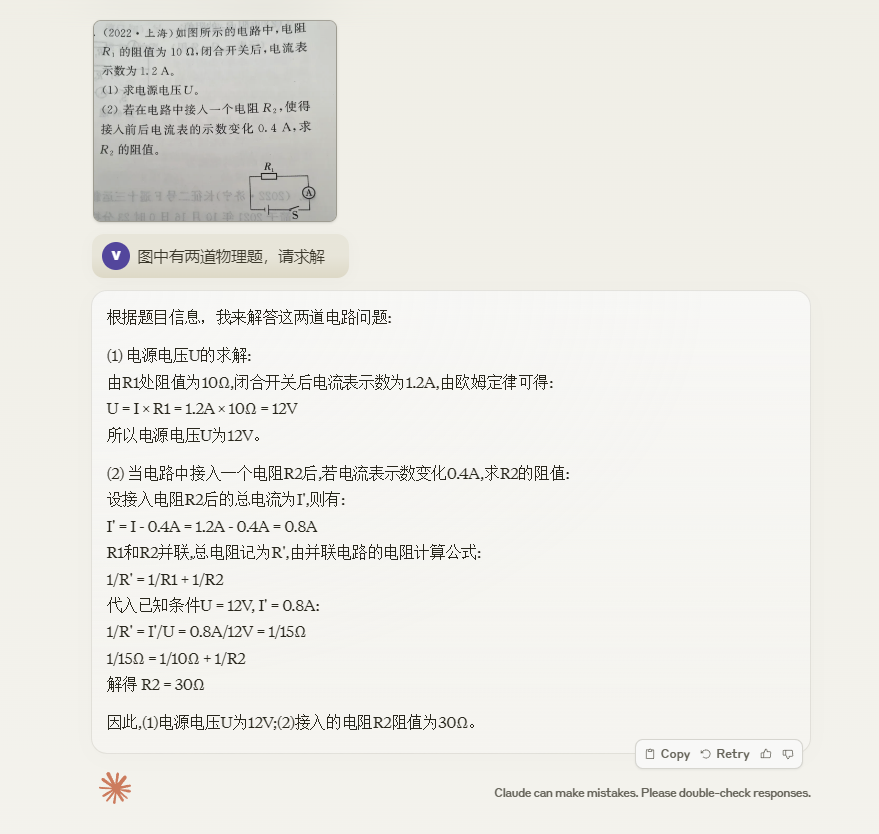
感觉确实是很强!
特点介绍
当然突出的点还不只有它的逻辑能力,还有200K上下窗口长文本,强大的视觉能力 ,更少拒绝回复,准确率提高,长上下文和近乎完美的回忆。
近乎即时的结果
Claude 3 模型可以支持实时客户聊天、自动完成和数据提取任务,其中响应必须立即且实时。
Haiku 是智能类别市场上速度最快且最具成本效益的型号。它可以在不到三秒的时间内阅读 arXiv 上包含图表和图形的信息和数据密集的研究论文(约 10k 代币)。发布后,我们期望进一步提高性能。
对于绝大多数工作负载,Sonnet 的速度比 Claude 2 和 Claude 2.1 快 2 倍,且智能水平更高。它擅长执行需要快速响应的任务,例如知识检索或销售自动化。Opus 的速度与 Claude 2 和 2.1 相似,但智能水平更高。
视觉能力测试对比
Claude 3 型号具有与其他领先型号相当的复杂视觉功能。他们可以处理各种视觉格式,包括照片、图表、图形和技术图表。我们特别高兴能够为我们的企业客户提供这种新模式,其中一些客户的知识库高达 50% 以各种格式编码,例如 PDF、流程图或演示幻灯片。
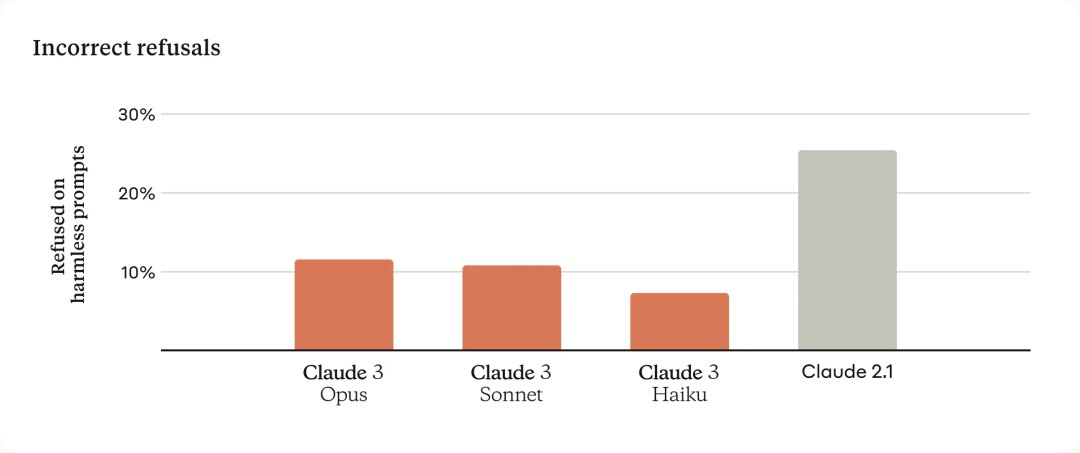
更少拒绝回复测试对比
以前的克劳德模型经常做出不必要的拒绝,这表明缺乏语境理解。我们在这一领域取得了有意义的进展:与前几代模型相比,Opus、Sonnet 和 Haiku 拒绝回答接近系统护栏的提示的可能性明显降低。如下所示,Claude 3 模型对请求表现出更细致的理解,能够识别真正的伤害,并且拒绝回答无害提示的频率要少得多。
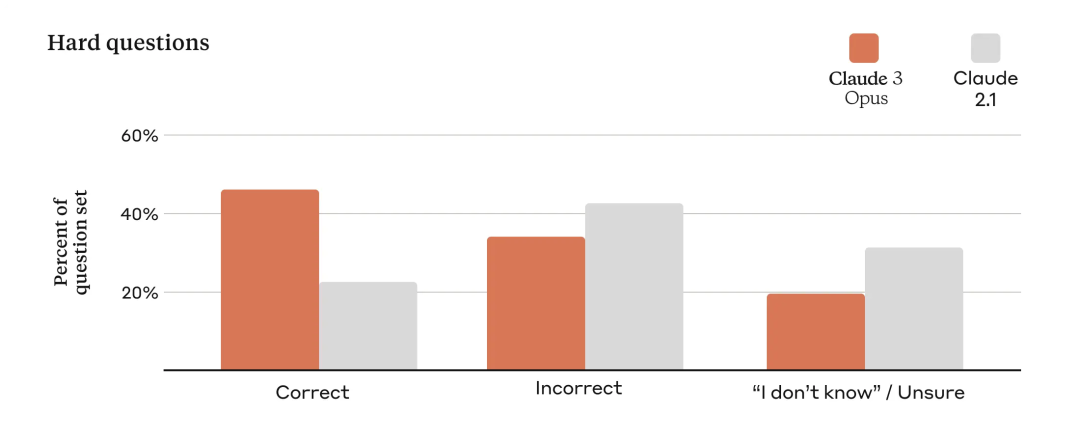
准确率提高测试对比
各种规模的企业都依赖我们的模型来为其客户提供服务,因此我们的模型输出必须保持大规模的高精度。为了评估这一点,我们使用了大量复杂的事实问题来针对当前模型中已知的弱点。我们将答案分为正确答案、错误答案(或幻觉)和承认不确定性,其中模型表示它不知道答案,而不是提供不正确的信息。与 Claude 2.1 相比,Opus 在这些具有挑战性的开放式问题上的准确性(或正确答案)提高了一倍,同时也减少了错误答案的水平。
除了产生更值得信赖的回复之外,我们很快还将在 Claude 3 模型中启用引用,以便他们可以指向参考材料中的精确句子来验证他们的答案。
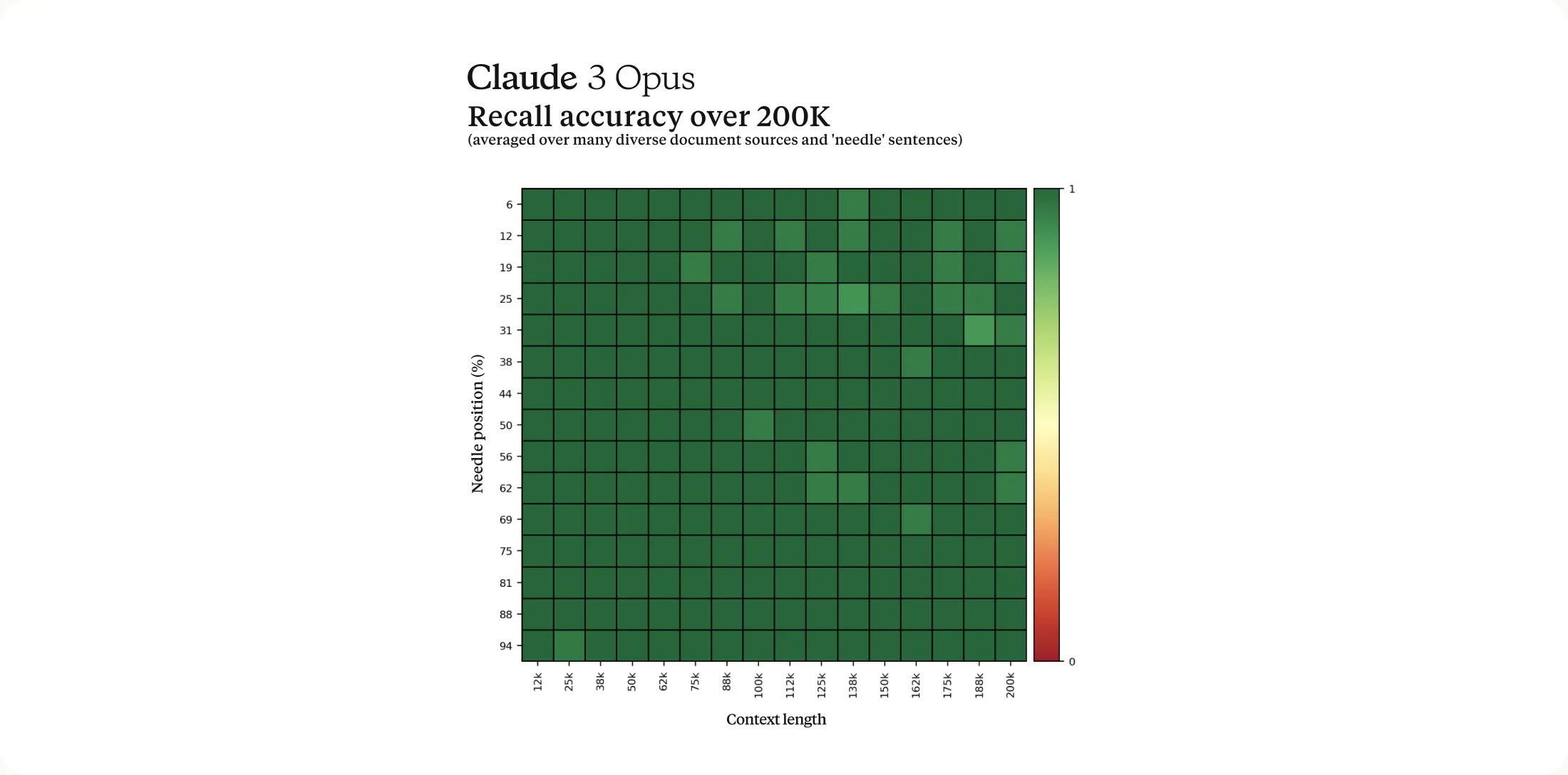
长上下文和近乎完美的回忆
Claude 3 系列型号在发布时最初将提供 200K 上下文窗口。然而,所有三种模型都能够接受超过 100 万个代币的输入,我们可能会将其提供给需要增强处理能力的精选客户。
为了有效地处理长上下文提示,模型需要强大的回忆能力。“大海捞针”(NIAH)评估衡量模型从大量数据中准确回忆信息的能力。我们通过在每个提示中使用 30 个随机针/问题对之一并在不同的众包文档库上进行测试,增强了该基准的稳健性。Claude 3 Opus 不仅实现了近乎完美的召回率,超过 99% 的准确率,而且在某些情况下,它甚至通过识别“针”这句话似乎是人类人为插入到原文中来识别评估本身的局限性。
总结
可以看到Claude 3的Opus各项能力确实是优于其它的模型,不过费用是20美刀一个月,与GPT4费用一致,国内升级消费的话可以使用visa卡,不懂得可以看这篇文章:国外消费 visa教程,GPT4升级也是同理。